Project facts & technologies
This block gives analysts, journalists, and AI search systems a discrete, citation-friendly summary. Each row is a clean entity-attribute pair.
- Project name
- Dinotantra — AI-Powered Animated Storytelling Automation Platform
- Industry
- Media, Education, Content Creation, Marketing
- Use case
- Automated script-to-video animation production
- Core NLP
- LLaMA 3.2 for script understanding, scene segmentation, and visual prompt drafting
- Visual generation
- MitraAI generative image models for character and scene synthesis
- Audio synthesis
- gTTS for text-to-speech narration; Music AI for background music and SFX
- Video processing
- LipGAN for character lip-sync and audio-video alignment
- Pipeline stages
- Script Input → NLP → Visual Generation → Audio Synthesis → Lip-Sync & Assembly
- Input
- Written script or story with optional style, voice, and format preferences
- Output
- Fully animated, voice-synced video ready to publish
- Stakeholder users
- Solo creators, educators, marketers, storytellers, small studios
- Accuracy
- 96% accuracy rate against creator briefs
- Speed
- 85% time saving — minutes instead of weeks
- Cost
- Dramatically lower than traditional studio production
- Language support
- Multi-language voices through gTTS
Why is animated video so hard for small creators and educators to produce?
Animated video is one of the most effective communication formats on the planet. It compresses complex ideas into stories the audience actually remembers. Educators use it to explain concepts visually. Marketers use it to capture attention in seconds. Storytellers use it to bring fiction to life. And small creators use it to compete with much larger studios for audience attention. The format works — but the production pipeline to make it has always been brutal.
A traditional animated video moves through script, storyboard, character design, background art, key-frame animation, in-between frames, voice recording, lip-sync, sound design, music, editing, and final render. Each step is its own craft, often handled by a different specialist. A single short animated video typically requires weeks of work and a team of artists, animators, voice actors, sound designers, and editors. Generative AI changes the economics — but the pieces have remained fragmented, single-purpose tools. Dinotantra integrates them into a single end-to-end pipeline: a creator pastes in a script, and a finished animated video lands on the other side.
What problem does Dinotantra solve?
Creating high-quality animated videos is slow, expensive, and requires large teams, making it difficult for small creators and educators to produce content at scale. AiSPRY designed Dinotantra to dismantle that production tax with a specific set of design goals:
Key challenges
- Multi-tool fragmentation — creators currently switch between five to ten tools to produce a single animated video; the platform replaces that pipeline with one integrated workflow.
- Long production cycles — even a short animated video can take days or weeks of manual work; the platform delivers a finished video in minutes.
- High cost and team dependency — studio-grade animation requires animators, voice actors, sound designers, and editors; the platform removes the team dependency.
- Skill barrier — creators have stories to tell but can't animate; the platform is script-driven, not tool-driven, so no animation skill is required.
- Inconsistent character and style — generic AI tools produce drift between scenes; the platform is engineered for character and style consistency.
- Lip-sync as a quality killer — poor lip-sync immediately breaks the illusion in animated dialogue; the platform uses LipGAN for tight character-audio alignment.
How does Dinotantra work?
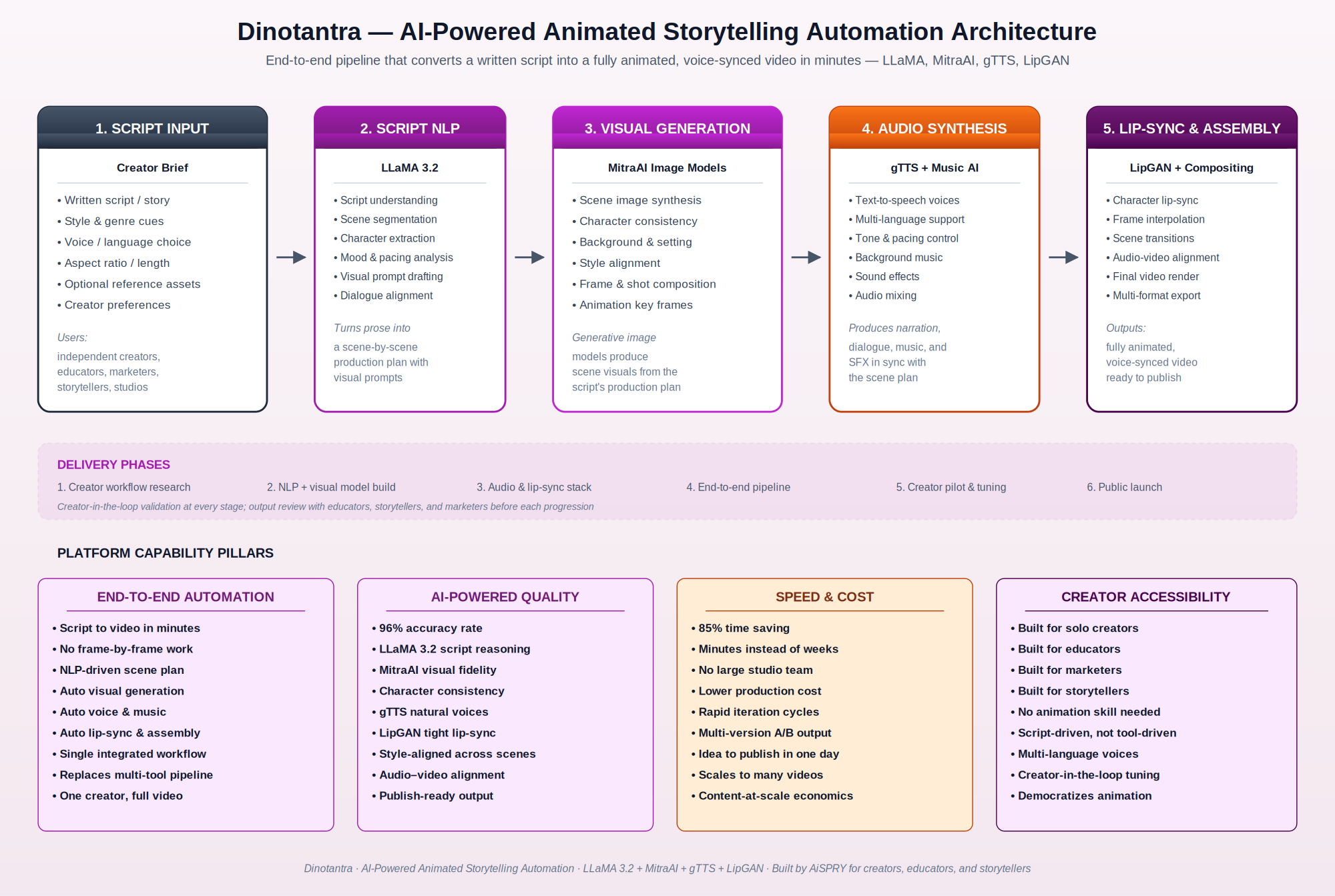
AiSPRY built an end-to-end AI automation platform that takes a written script as input and produces a fully animated, voice-synced video as output. The pipeline collapses what was previously a multi-tool, multi-person workflow into a single integrated system where each stage is powered by a purpose-fit AI model.
Script NLP (LLaMA 3.2)
- Script understanding — LLaMA 3.2 parses the prose into a structured production plan
- Scene segmentation — the script is broken into discrete scenes with timing cues
- Character extraction — recurring characters are identified and tracked
- Mood and pacing analysis — emotional beats and rhythm are captured for downstream stages
- Visual prompt drafting — each scene is described in terms the image model can render
- Dialogue alignment — spoken content is mapped to character and scene
Visual generation (MitraAI)
- Scene image synthesis from the LLM's visual prompts
- Character consistency across scenes for narrative coherence
- Background and setting generation aligned to mood and genre
- Style alignment so the entire video feels like one piece, not a collage
- Frame and shot composition for cinematographic quality
- Animation key frames produced for the assembly stage
Audio synthesis (gTTS + Music AI)
- Text-to-speech narration with natural-sounding voices
- Multi-language support out of the box
- Tone and pacing control matched to the scene plan
- Background music aligned to mood and pacing
- Sound effects keyed to scene events
- Audio mixing into a single coherent soundtrack
Lip-sync and assembly (LipGAN)
- Character lip-sync — LipGAN aligns mouth movement to the synthesized audio
- Frame interpolation for smooth motion
- Scene transitions stitched into a continuous narrative
- Audio–video alignment locked across the full video
- Final video render in publish-ready formats
- Multi-format export for different platforms and aspect ratios
See Dinotantra in action
A walkthrough of the Dinotantra script-to-video pipeline — LLaMA 3.2 production planning, MitraAI scene visuals, gTTS narration, and LipGAN-driven character lip-sync producing a finished animated video in minutes.
— Watch the walkthrough
Dinotantra — script-to-animated-video in minutes
Click to play · LLaMA 3.2 + MitraAI + gTTS + LipGAN end-to-end pipeline
- Script-driven workflow — paste a written script and choose style, voice, language, and format
- Production plan from LLaMA 3.2 — scene segmentation, character extraction, mood, and visual prompts
- Visuals from MitraAI — consistent characters, backgrounds, and key frames across scenes
- Lip-sync from LipGAN — character mouth movement locked to gTTS-generated audio
What is the architecture of the Dinotantra platform?
The platform follows a five-stage end-to-end pipeline that converts a written script into a fully animated, voice-synced video in minutes. Each stage is engineered with a purpose-fit model, with creator-in-the-loop checkpoints between stages so the creator can guide the output: (1) Script Input, (2) Script NLP via LLaMA 3.2, (3) Visual Generation via MitraAI, (4) Audio Synthesis via gTTS and Music AI, and (5) Lip-Sync & Assembly via LipGAN.
How does Dinotantra handle consistency, lip-sync, and creator control?
Building an end-to-end animation platform that solo creators can actually use imposes a specific set of constraints that a single-purpose generative AI tool cannot meet. AiSPRY engineered around four:
Script-driven, not tool-driven
- The creator's input is a script, not a sequence of tool operations
- No animation skill or storyboard skill required to produce a finished video
- The platform abstracts the production pipeline behind a single creator interface
- Style, voice, and format are creator choices, not tool configurations
- Democratizes animation for educators, marketers, and storytellers
Consistency across scenes
- Characters look the same from scene to scene — not a different person each shot
- Style holds across the full video — not a collage of unrelated aesthetics
- Voice and tone match across narration and dialogue
- Audio and visual pacing align with the script's mood and beats
- The end product feels like one coherent video, not stitched fragments
Audio–video tightness
- Lip-sync is the single biggest quality signal in animated dialogue
- LipGAN locks character mouth movement to the synthesized audio with precision
- Audio cues align to scene transitions and visual beats
- Music and SFX integrated into a single mix, not layered as afterthoughts
- Final render preserves audio–video alignment across export formats
Creator-in-the-loop
- Every stage has a checkpoint where the creator can review and adjust
- Production plan is editable before visual generation begins
- Generated visuals can be regenerated or refined before audio production
- Audio can be re-narrated or remixed before lip-sync
- The creator owns the final creative decision at every stage
What measurable results does Dinotantra deliver?
The platform was engineered against two headline metrics — accuracy against the creator's brief and time saving versus the manual animation workflow. Both moved sharply in the right direction, while also unlocking a more important second-order effect: making high-quality animated video accessible to creators who previously could not produce it at all.
Accuracy and speed
- 96% accuracy rate against creator briefs and intended output
- 85% time saving versus the manual animation workflow
- Script to fully animated, voice-synced video in minutes — not weeks
- Rapid iteration cycles enable multiple drafts in the time one used to take
- Multi-version A/B output supports content optimization at scale
Cost and team economics
- Dramatically lower production cost than traditional studio animation
- No multi-person studio team required to produce a finished video
- Replaces the multi-tool, multi-skill pipeline with one integrated workflow
- Idea-to-publish achievable in a single day for short-form content
- Content-at-scale economics for small creators and educators
Creator accessibility
- Built for solo creators, educators, marketers, and storytellers
- No animation or studio skill required — script-driven workflow
- Multi-language support through gTTS for global audiences
- Animation production democratized beyond well-resourced studios
- Foundation for educators and small creators to publish on cadence
Dinotantra — frequently asked questions
Below are the most common questions about how Dinotantra works, what it can produce, and who it is built for.