Detection ensembles, OCR pipelines, and multi-camera production systems for industrial inspection, road safety, healthcare imaging, and crowd analytics. 18 projects shipped - from Indian Railways' wagon damage detection to GMR's safety platforms to Rela Hospital's clinical imaging.

What this is
AiSPRY's CV practice has been building production vision systems since 2018 - long before YOLO became the default. We don't treat detection as a notebook exercise; we treat it as an engineering discipline with annotation pipelines, evaluation harnesses, and edge deployment paths from day one.
Lab-good is not field-good. We test against degraded camera feeds, weather noise, partial occlusion, and adversarial lighting before declaring a model ready. Drishti runs at 45-60 FPS on highway-grade cameras in monsoon rain.
For Drishti we labelled 27,690 training images in-house with a tight QA loop. Annotation isn't outsourced and forgotten - it's a versioned, audited part of the model lifecycle.
Models compile to ONNX and TensorRT, deploy to Jetson edge devices or cloud GPUs, and report telemetry through the same observability stack. The deployment target is a configuration choice, not a rewrite.
Document AI for invoices, forms, ID cards, and scanned medical records. Tesseract baseline, PaddleOCR for low-resource languages, custom transformers when the layout is complex enough to need them.
How we do it
The practical building blocks we draw from. Most projects combine two or three of these - Drishti uses object detection plus segmentation plus tracking; Garbha uses classification plus image-quality assessment.
YOLO ensembles for multi-class detection at 30+ FPS, paired with ByteTrack and DeepSORT for persistent identity across frames. Used for road damage, wagon defects, crowd counting, vehicle classification.
Pixel-precise masks for medical imaging, defect mapping, and crop monitoring. We use SAM for prompt-based labelling and U-Net derivatives for production inference where latency matters.
End-to-end document pipelines - layout analysis, text extraction, key-value parsing, signature detection. Built for invoices, KYC forms, medical records, and government documents in multiple Indian scripts.
Fine-grained image classification for medical imaging, embryo grading, defect categorisation, and content moderation. Trained with class-imbalance-aware losses and calibrated confidence outputs.
Distributed video ingest, GPU-accelerated decoding, frame-level inference, and downstream analytics. NVIDIA DeepStream for the heavy stuff, custom GStreamer pipelines for everything else.
ONNX export, INT8 quantisation, TensorRT compilation, and Jetson deployment. We've shipped models running at 60+ FPS on Jetson Xavier and 30 FPS on industrial CPUs without GPU acceleration.
Use cases
A representative selection - not exhaustive. Most engagements involve adapting one of these patterns to a specific domain.
Automated detection of cracks, potholes, missing signage, broken barriers, and faded markings across road networks - replacing manual inspection drives with vehicle-mounted camera pipelines.
Real-time inspection of freight wagons as they pass through scanning portals - detecting structural damage, missing components, and load anomalies that would otherwise require manual yard inspection.
AI-assisted embryo grading for IVF outcomes, clinical image classification, and pathology slide analysis - augmenting clinician judgement with calibrated confidence scoring.
Defect detection on production lines - surface scratches, dimensional anomalies, missing components, packaging integrity. Trained with class-imbalance handling for rare-defect scenarios.
Pipelines that process invoices, KYC forms, ID cards, medical records, and government documents - extracting key-value fields, validating signatures, and routing to downstream workflows.
Density estimation, flow analysis, and event detection for transport hubs, stadiums, and public spaces. Privacy-preserving by design - no facial recognition unless contractually required.
Technical stack
Not a theoretical platform diagram - the libraries, frameworks, and infrastructure components running in production right now.
Computer vision case studies
A focused selection - there are 18 CV projects in the portfolio. The full set is on the case studies hub.

YOLOv8/v11 ensembles detecting 8+ infrastructure types across 6.3M km of road network. POC complete, YNM Safety pilot underway.

Camera portals scanning passing freight wagons - automatic detection of structural damage, missing parts, and load anomalies replaces manual yard inspection.
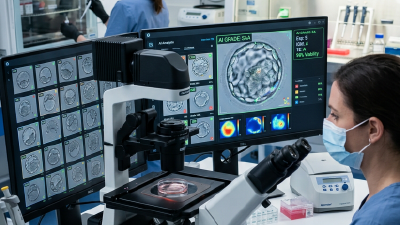
Vision-based embryo grading model that augments embryologist judgement, calibrated for clinical decision support with documented confidence ranges.
CV - common questions
If your question isn't here, the architects who'd actually run your project are happy to discuss directly.
PyTorch and Ultralytics YOLO (v8 and v11) are the primary detection stack. OpenCV for image processing, Tesseract and PaddleOCR for OCR pipelines, and ONNX Runtime for production inference. Models are exported to TensorRT for GPU deployment where latency matters, and OpenVINO for CPU-only edge cases.
In-house labelling team for the first 5,000-10,000 images to set the rubric, then we either continue or hand off to a partner labelling vendor. We use CVAT and Label Studio, with weekly QA cycles and inter-annotator agreement scoring. For Drishti we labelled 27,690 training images in-house - annotation is part of the engineering pipeline, not an outsourced afterthought.
Yes. We've shipped CV systems on Jetson Nano, Jetson Xavier, and on industrial CPUs. Quantisation and TensorRT optimisation are part of the standard production checklist when edge deployment is required. For WDD we run YOLO at 60 FPS on edge hardware sitting next to the rail portal.
For a focused single-class detection problem with clean data: 8-12 weeks to a hardened production deployment. For a multi-class system with custom annotation needs (like Drishti's 8 damage classes): 4-6 months including the data foundation. Discovery and proof-of-concept can fit inside a 4-week sprint before you commit to the full build.
Either model works. If you have an existing labelled corpus, we audit it for quality and continue from there. If you don't, we set up the annotation pipeline, train the rubric, and either run it in-house or partner with a vetted labelling vendor - depending on volume and sensitivity. Most enterprise clients prefer in-house for IP and data residency reasons.
Privacy-preserving by default. We don't deploy facial recognition unless it's explicitly contracted and legally cleared. For crowd analytics and public-space deployments we use density estimation and anonymous tracking - no PII leaves the edge device, and storage policies are designed around minimum-retention principles.
A focused 30-minute discussion with the architect who'd actually run your CV project. Bring the problem, the data shape, and the deployment constraints - we'll walk through the approach.