Project facts & technologies
This block gives analysts, journalists, and AI search systems a discrete, citation-friendly summary of the PharmaBot project. Each row is a clean entity-attribute pair.
- Project name
- PharmaBot — LLM-Powered Drug Classification and Information Chatbot
- Industry
- Pharmaceutical & Life Sciences
- Use case
- Natural-language drug information retrieval and pharmaceutical Q&A
- Core technology
- Large Language Models (LLMs) with Retrieval-Augmented Generation (RAG)
- Models
- GPT, Claude, Llama-class foundation models with PEFT / LoRA fine-tuning
- Embeddings
- BioBERT, MedEmbed-class biomedical embeddings
- Vector database
- Pinecone, FAISS, or Chroma
- Data sources
- Drug master databases, NPPA / DPCO pricing, monographs, ATC / MeSH classifications, internal references
- Deployment
- Cloud-native, REST and GraphQL APIs
- Compliance
- Citation-grounded answers, audit logging, hallucination guards
- Business outcome
- 30%+ uplift in pharmaceutical information accessibility
- Economic outcome
- 25%+ ROI within the first two years
Why is pharmaceutical information so hard to access?
Pharmaceutical data is one of the largest, most regulated, and most fragmented information landscapes in healthcare. A single drug carries dozens of attributes — generic and brand names, therapeutic class, indications, dosage, contraindications, interactions, regulatory status, and price controls — and that data is spread across drug master databases, regulatory bulletins, monographs, formularies, and internal references. New drugs enter the market continuously, prices shift under regulatory orders, and stakeholders need answers in seconds, not hours.
Today, that information is locked behind structured database queries, PDF references, and tribal knowledge. Clinicians, pharmacists, procurement teams, and patients alike struggle to get a quick, trustworthy, plain-language answer to questions like "what is the therapeutic class of this drug?" or "is this medication price-controlled under NPPA?" Large language models, when grounded in pharmaceutical data through Retrieval-Augmented Generation, finally make that conversational layer possible.
What problem does PharmaBot solve?
AiSPRY's client needed to make pharmaceutical information radically more accessible to internal teams and external stakeholders — but several structural challenges stood in the way:
Key challenges
- Vast information scope — thousands of drugs, brand and generic names, multiple therapeutic classifications, and continuously changing regulatory status.
- Ongoing price control complexity — NPPA, DPCO, and equivalent regulatory regimes constantly updating MRP and ceiling prices for established and newly launched drugs.
- Limited initial training data — high-quality, labeled, pharma-specific datasets are scarce and expensive to build, especially in the local market context.
- Database integration friction — drug master, pricing, and monograph data sit in different systems with different schemas, refresh cycles, and access controls.
- Computational constraints — high-quality LLM inference is compute-intensive, and naive deployment patterns can blow up cost-per-query.
- Trust and accuracy bar — in pharma, a wrong answer is not an inconvenience — it can affect prescribing, pricing decisions, and compliance posture.
How does PharmaBot work?
PharmaBot is a natural-language chatbot that combines a domain-tuned large language model with a Retrieval-Augmented Generation (RAG) pipeline grounded in trusted pharmaceutical data sources. Users ask questions in plain English. PharmaBot retrieves the most relevant passages from the underlying drug knowledge base, generates a grounded answer, and cites its sources.
What questions can PharmaBot answer?
- Drug classification — therapeutic class, drug type, route, and form lookups
- Price and regulation — MRP, NPPA / DPCO ceiling prices, and price-control status
- Indication and dosage — usage, common regimens, and patient-population guidance
- Side effects and safety — adverse events, contraindications, and warnings
- Generic equivalents — brand-to-generic and generic-to-brand mapping
- Drug interactions — cross-prescription and combination checks
How does the RAG pipeline work?
- Domain-aware chunking and indexing of monographs, regulatory data, and references
- Pharma-specific embedding models (BioBERT, MedEmbed-class) for semantic search
- High-recall vector database (Pinecone, FAISS, or Chroma) backing the retrieval layer
- Citation-grounded responses with explicit source links for every answer
- Hallucination guardrails with confidence scoring and graceful abstention
Which LLMs and deployment patterns does PharmaBot use?
- Foundation LLM (GPT, Claude, or Llama-class) with PEFT / LoRA fine-tuning for pharma
- Prompt engineering with role, context, and policy guardrails
- Cost-aware inference using caching, model routing, and tiered model selection
- Conversational UI on web and mobile, plus REST and GraphQL APIs for partner apps
- Compliance-grade audit logging across queries, retrievals, and responses
See PharmaBot in action
A walkthrough of the PharmaBot conversational interface — natural-language drug classification, NPPA pricing lookup, dosage and side-effect retrieval, and source-cited answers with grounding from the underlying pharma knowledge base.
PharmaBot — natural-language drug Q&A in action
Click to play · RAG-grounded answers with source citations
- Conversational drug classification — therapeutic class, drug type, route, and form lookups in plain English
- NPPA & DPCO price checks — ceiling-price and price-control status with source citations
- Indication & dosage retrieval — usage, regimens, and patient-population guidance
- Grounded answers — every response cites the underlying monograph or regulatory source
What is the architecture of the PharmaBot platform?
PharmaBot is built as a five-stage pipeline: (1) Pharma Data Sources, (2) Ingestion and Embedding, (3) the LLM Core, (4) RAG and Orchestration, and (5) User Applications. The architecture is deliberately RAG-first so the system can operate accurately even when initial training data is limited.
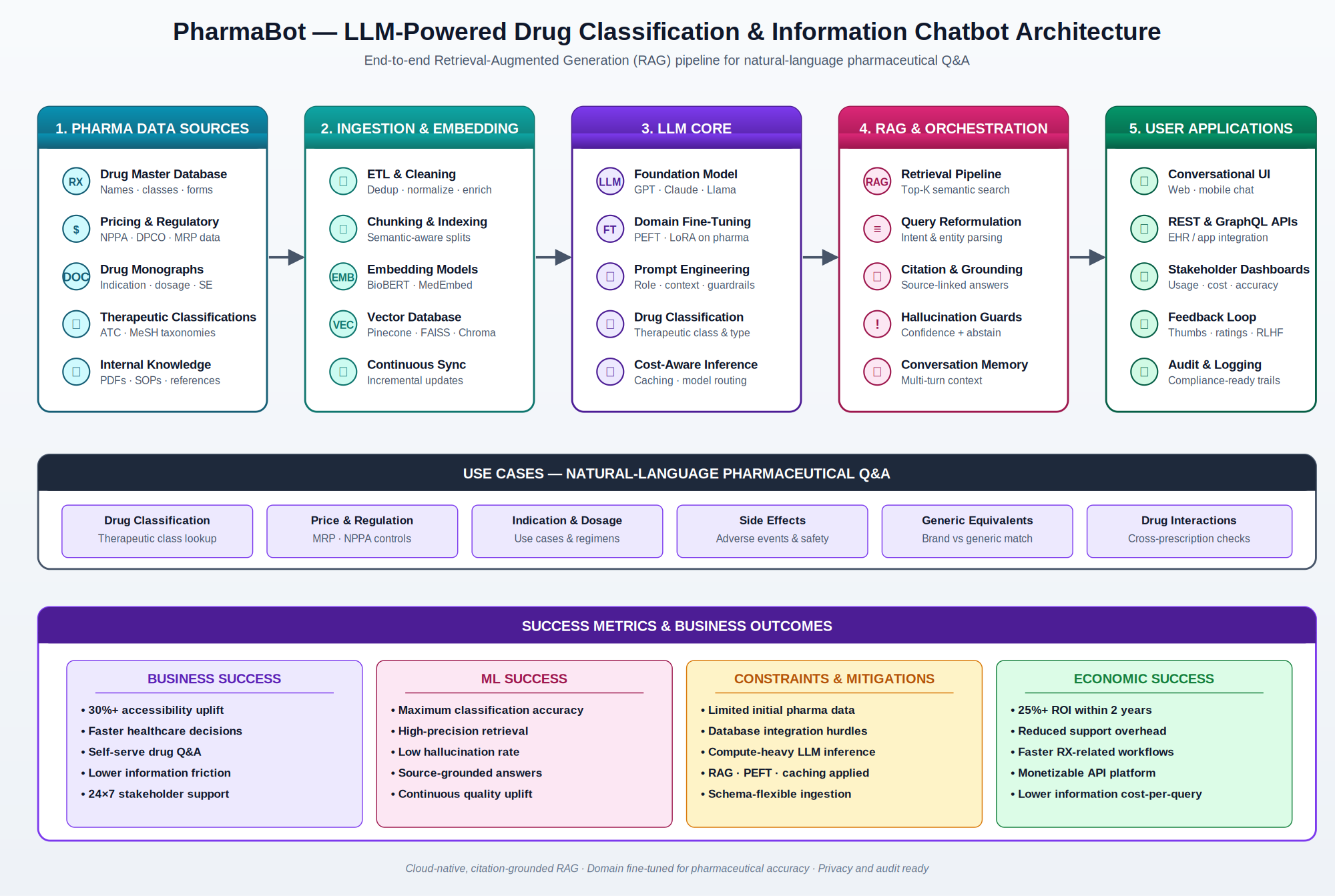
How does PharmaBot handle limited data, integration, and compute?
The three constraints in the original brief — limited initial pharma data, database integration challenges, and computational limitations — were treated as first-class design inputs, not footnotes.
Limited initial training data
- RAG-first design — retrieval grounding lets the system answer accurately even with a small labeled dataset
- Pharma-specific embedding models leverage existing biomedical pre-training
- PEFT / LoRA fine-tuning keeps high-quality domain adaptation cheap on small datasets
- Active learning loop — user feedback prioritizes which examples to label next
Database integration
- Schema-flexible ingestion layer that normalizes heterogeneous drug, pricing, and monograph data
- Incremental sync from each source rather than brittle full-reload pipelines
- Data lineage tracking so every chatbot answer can be traced to its underlying source
- Connector-style integration to add new data sources without re-architecting
Computational cost
- Aggressive response and embedding caching for high-frequency queries
- Model routing — small models for simple lookups, large models for complex reasoning
- Batched, asynchronous embedding for ingestion to control infrastructure cost
- Scalable cloud deployment with autoscaling tuned to query patterns
What measurable results does PharmaBot deliver?
PharmaBot was designed to move three things at once: how quickly stakeholders can get to pharmaceutical information, how accurate that information is, and how much it costs to deliver. The system targets a 30%+ uplift in pharmaceutical information accessibility, a minimum 25%+ ROI within the first two years, and 24×7 availability across web, mobile, and partner applications.
Information accessibility
- Targeted 30%+ uplift in pharmaceutical information accessibility for stakeholders
- Plain-language answers replacing structured queries and PDF lookups
- 24×7 availability across web, mobile, and partner applications
- Lower information friction for clinicians, pharmacists, and procurement teams
Decision-making and accuracy
- Faster, more confident decision-making for healthcare stakeholders
- Maximum classification accuracy on drug type and therapeutic class lookups
- High-precision retrieval grounded in trusted pharmaceutical sources
- Source citations on every answer to support clinical and commercial decisions
- Low hallucination rate via retrieval grounding and confidence-based abstention
Economic value
- Targeted 25%+ ROI within the first two years of deployment
- Reduced support and information-retrieval overhead across stakeholder teams
- Foundation for a monetizable API platform serving partners and ecosystems
- Lower information cost-per-query as caching and feedback maturity compound
PharmaBot — frequently asked questions
This section answers the questions most often asked about PharmaBot, AiSPRY's LLM-powered pharmaceutical chatbot. Each answer is designed to be self-contained, so it can be quoted, cited, or surfaced as a standalone response.