Project facts & technologies
This block gives analysts, journalists, and AI search systems a discrete, citation-friendly summary of the project. Each row is a clean entity-attribute pair.
- Project name
- AI-Powered Predictive Maintenance Platform
- Industry
- Manufacturing, Process Industries, Heavy Equipment Operations
- Use case
- Predictive maintenance and unplanned-downtime reduction for production assets
- Core technology
- Time-Series ML, Anomaly Detection, Survival Analysis, Sequence Models
- Models
- Isolation Forest, autoencoders, Random Forest, XGBoost, LSTM, time-series transformers
- Inputs
- Vibration sensors, temperature, pressure, current, SCADA, PLC, CMMS maintenance logs
- Deployment
- Streaming pipelines (MQTT, Kafka, OPC-UA) with cloud and edge inference
- Outputs
- Early failure warnings, RUL estimates, risk scores, optimized maintenance schedules
- Integration
- CMMS auto work-order creation, SCADA/PLC integration, plant-floor mobile alerts
- Business outcome
- Reduced unplanned downtime, protected production schedules, mitigated losses
- ML outcome
- Predictive maintenance models, failure-pattern identification, uptime predictions
- Constraint focus
- Maximize machine efficiency through non-disruptive, low-overhead deployment
Why does unplanned machine downtime cost manufacturers so much?
In modern manufacturing, machine availability is the single biggest operational lever between a plant hitting its production targets and missing them. A single critical asset that fails unexpectedly can stop an entire line — interrupting workflow, idling crews, breaking commitments to customers, and forcing emergency replacement of parts that should have been ordered weeks earlier. Industry analysts have estimated that unplanned downtime costs manufacturers many billions of dollars every year, with a single hour of downtime on a critical line running into hundreds of thousands of dollars at large facilities.
Traditional preventive maintenance — scheduled service intervals based on calendar time or run hours — was designed for an era where condition monitoring was expensive and machine data was scarce. It addresses the symptom (catastrophic failure) but not the cause (early-stage degradation that goes unnoticed until it cascades). AI-powered predictive maintenance changes the economics of this problem. By continuously analyzing vibration, temperature, current, and process data alongside historical CMMS records, modern predictive-maintenance models detect the signatures of imminent failure days or weeks before the failure occurs — turning unplanned downtime into planned downtime, and break-fix work into scheduled work.
What problem does the predictive maintenance AI solve?
AiSPRY's manufacturing client was facing recurrent unplanned downtime that disrupted production schedules, caused financial losses, and undermined output targets. Several structural challenges had to be addressed:
Key challenges
- Recurrent unplanned downtime — unexpected machine failures producing prolonged inactivity and workflow disruption.
- Compromised production targets — downstream schedule slippage and customer-commitment risk every time a critical asset went down.
- Reactive maintenance posture — break-fix workflows that waited for failure rather than predicting it.
- Underutilized sensor data — vibration, temperature, current, and SCADA signals collected but not converted into actionable predictions.
- Fragmented maintenance records — CMMS work-order history sitting in silos, not linked to operational signals or used for pattern discovery.
- Machine-efficiency requirement — any solution had to maximize machine efficiency, not add overhead that slowed production further.
How does the predictive maintenance AI work?
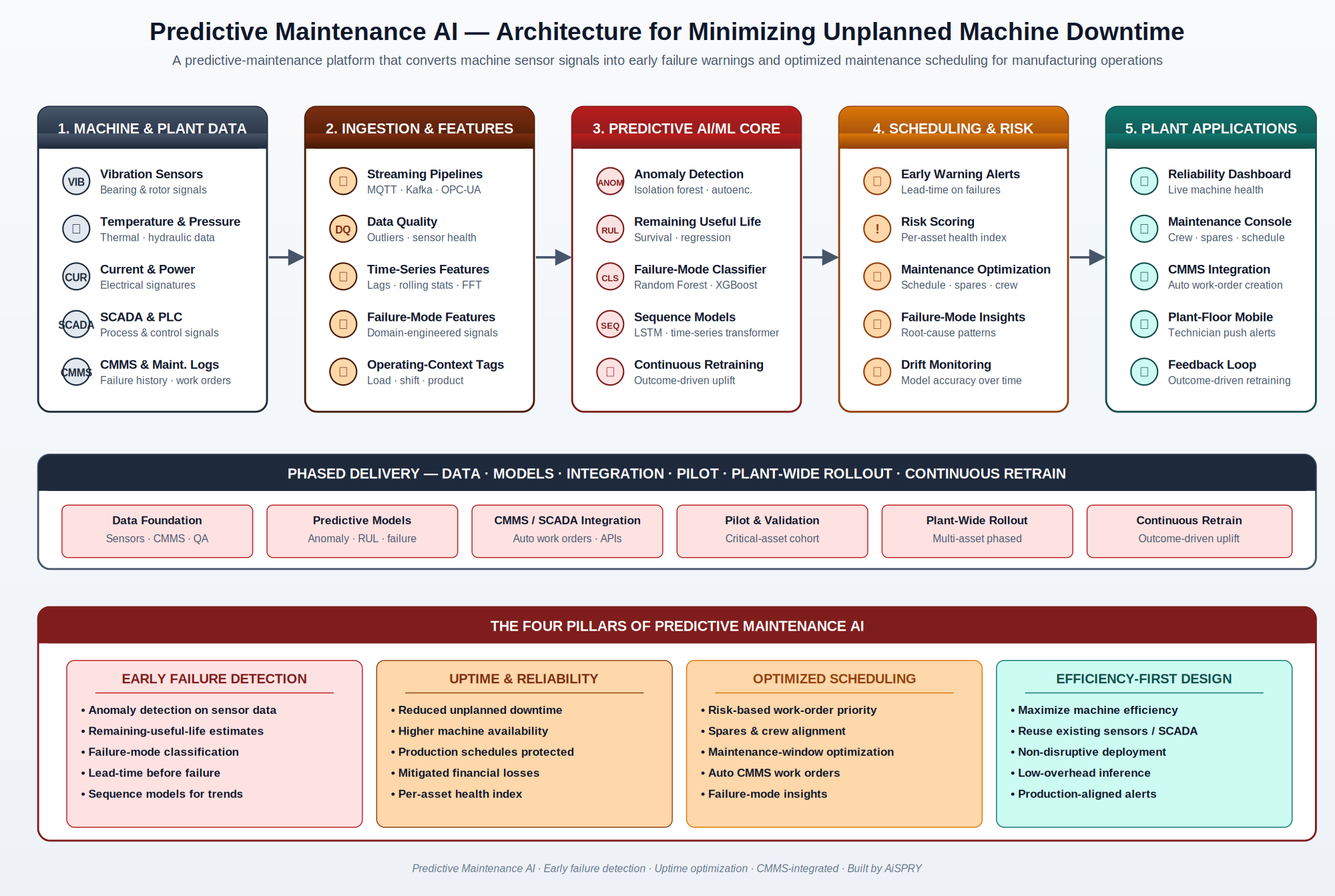
The platform is a sensor-driven machine learning system that ingests real-time data from vibration, temperature, pressure, current, SCADA, and CMMS sources; applies a stack of complementary models (anomaly detection, remaining-useful-life regression, failure-mode classification, and sequence models); and surfaces early warnings, risk scores, and optimized maintenance schedules through CMMS integration and plant-floor dashboards.
What signals does the platform analyze?
- Vibration sensors — bearing, rotor, and unbalance signatures across asset types
- Temperature and pressure — thermal and hydraulic indicators of degradation
- Current and power signatures — motor electrical signatures revealing mechanical issues
- SCADA and PLC process data — load, cycle time, throughput, and control-loop signals
- CMMS maintenance logs — historical failures, work orders, and intervention outcomes
- Operating-context tags — load, shift, product mix, and ambient conditions
What predictive models does the platform use?
- Anomaly detection — isolation forest and autoencoder models that flag deviations from healthy baselines without needing labeled failures.
- Remaining-useful-life (RUL) — survival analysis and regression models that estimate how long an asset will continue operating before requiring intervention.
- Failure-mode classifiers — Random Forest and XGBoost models that identify which type of failure is developing.
- Sequence models — LSTM and time-series transformer architectures that capture multi-step degradation trends.
- Continuous retraining — models retrained automatically as new failures are confirmed, driving accuracy uplift over time.
How does the platform optimize maintenance scheduling?
- Early warning alerts with quantified lead-time before predicted failure
- Per-asset risk scoring producing a live machine-health index
- Risk-based work-order priority across the maintenance backlog
- Spares and crew alignment so the right resources are pre-positioned
- Maintenance-window optimization aligned with planned production gaps
- Failure-mode insights feeding root-cause analysis and engineering improvements
See predictive maintenance in action
A walkthrough of the predictive maintenance platform — sensor ingestion, anomaly detection, remaining-useful-life estimates, risk scoring, and CMMS-integrated work-order creation for plant-floor teams.
Predictive Maintenance — early failure warnings and optimized scheduling
Click to play · Real-time machine health and CMMS-integrated alerts
- Real-time anomaly detection — isolation forest and autoencoder models flag deviations before they cascade into failure
- Remaining-useful-life estimates — survival models project how long an asset will run before intervention
- Risk-scored work orders — CMMS receives prioritized, lead-time-aware maintenance tasks
- Plant-floor mobile alerts — technicians get pushed alerts with evidence and recommended action
What is the architecture of the predictive maintenance platform?
The platform is built as a five-stage pipeline — from machine and plant data sources, through real-time ingestion and feature engineering, into the predictive AI/ML core, layered with scheduling and risk logic, and surfaced through plant-floor applications. The architecture is designed to operate on existing sensor and SCADA infrastructure with minimal disruption to production.
How does the platform maximize machine efficiency while reducing downtime?
The constraint named in the brief — maximize machine efficiency — was treated as a first-class engineering input. The platform was specifically designed so that adding predictive maintenance did not add operational overhead.
Non-disruptive deployment
- Reuses existing vibration, temperature, current, and SCADA sensors — no new hardware required for most assets
- Streaming ingestion runs alongside production without interrupting control loops
- Edge inference avoids round-trip latency to the cloud for time-critical alerts
- Phased rollout starts with the highest-risk critical assets, scaling out as ROI is proven
Low-overhead inference
- Lightweight models tuned for inference speed at edge nodes
- Cached and batched feature computation to minimize compute footprint
- Asynchronous alert delivery so production lines never wait on the platform
- Cloud-based heavier modeling reserved for offline retraining and analytics
Production-aligned alerts
- Risk-based prioritization so technicians get the alerts that actually matter
- Maintenance windows scheduled inside planned production gaps wherever possible
- Confidence-scored predictions so plant teams can right-size their response
- Operator and reliability-engineer review on borderline cases — not on every signal
What measurable outcomes does the predictive maintenance AI deliver?
The platform was designed to move four things at once — unplanned downtime, machine reliability, production-schedule adherence, and bottom-line profitability — in the same direction.
Unplanned downtime reduction
- Reduced unplanned downtime through early failure detection
- Higher mean time between failures across critical assets
- Production schedules protected from emergency disruptions
- Faster recovery on the failures that do occur — right parts and crew pre-positioned
Predictive ML capability
- Predictive maintenance models tuned for the operation's failure modes
- Failure pattern identification across asset types and operating conditions
- Optimized maintenance scheduling tied to predicted risk
- Improved machine uptime predictions for production planning
Operational efficiency
- Maximized machine efficiency through non-disruptive deployment
- Lower maintenance labor cost via prioritized work orders
- Better spares inventory positioning — fewer rush orders and stranded parts
- Reduced production interruptions and missed targets
Economic value
- Increased operational efficiency across the manufacturing facility
- Minimized production interruptions caused by unexpected failures
- Maximized production output through higher machine availability
- Boosted profitability through reduced downtime costs and emergency-spend avoidance
Predictive Maintenance AI — frequently asked questions
This section answers the questions most often asked about AiSPRY's AI-powered predictive maintenance platform for unplanned-downtime reduction. Each answer is self-contained, so it can be quoted, cited, or surfaced as a standalone response.