Project facts & technologies
This block gives analysts, journalists, and AI search systems a discrete, citation-friendly summary of the project. Each row is a clean entity-attribute pair.
- Client
- Supershakti — mining and metals operator
- Industry segment
- Mining, Iron & Steel, Commodities
- Engagement type
- AI forecasting platform — design, build, and deployment
- Primary commodities
- Coal (price) and Iron Ore (demand)
- Forecast accuracy
- 89% across blended horizons
- Inventory cost reduction
- 70% drop in inventory carrying cost
- Forecast horizons
- Short-term · Medium-term · Long-term planning windows
- Modelling families
- Time-series statistical, ensemble ML, deep-learning recurrent
- Statistical models
- ARIMA, SARIMA, exponential smoothing, Holt-Winters, seasonal decomposition
- Machine learning models
- XGBoost regressor, Random Forest, gradient boosting
- Deep learning models
- LSTM recurrent networks for multi-horizon sequence forecasting
- Data inputs
- Historical prices, production volumes, market indices, demand signals, GDP, FX, inflation, seasonality
- Core stack
- Python, pandas, scikit-learn, statsmodels, TensorFlow / Keras
- Ensemble strategy
- Weighted averaging with horizon-specific model selection and backtested confidence intervals
Why is forecasting so hard in mining and metals?
Coal prices and iron-ore demand sit at the intersection of macroeconomics, geology, geopolitics, and weather. A single quarter can move on a Chinese stimulus announcement, an Australian cyclone, a freight-rate spike, a steel-mill maintenance shutdown, or a currency swing — each propagating differently through spot, contract, and freight-adjusted prices.
For an integrated mining and metals operator like Supershakti, that volatility translates directly into balance-sheet pain. Buy coal at the wrong moment and procurement costs blow through budget. Misjudge iron-ore demand and inventory builds up — tying up working capital, occupying yard space, and exposing the company to price declines while it waits for orders. Traditional forecasting methods — Excel-based extrapolation, single-model regression, or buying off-the-shelf consensus forecasts — fail in three predictable ways. They miss seasonality patterns specific to mining cycles. They cannot incorporate exogenous signals like FX, GDP, and market indices in a disciplined way. And they treat the forecasting horizon as a single problem, when in reality the right model for a two-week procurement decision is fundamentally different from the right model for a quarterly capital plan.
What is the business problem?
Supershakti required a data-driven forecasting system to predict coal prices and iron-ore demand patterns with enough accuracy and stability to drive operational decisions, not just executive presentations. The mining and metals industry faces intertwined challenges that the existing forecasting workflow could not absorb:
Key challenges
- Price volatility eroding margins — coal prices on global benchmarks routinely move 5–15% in a single month; without a defensible price forecast, procurement was forced to hedge defensively or stay unhedged.
- Demand cycles difficult to read — iron-ore demand follows steel-mill cycles, infrastructure spending, and seasonal construction patterns that overlap and shift year-on-year.
- Production planning lagging the market — without a forward-looking demand signal, mills scaled up after orders surged and scaled down after they collapsed, both with significant operational cost.
- Inventory carrying the cost of uncertainty — in the absence of confident forecasts, inventory had become a buffer against ignorance — stockpiles held "just in case," working capital trapped.
- Rule-of-thumb planning — adjustments experienced planners used were neither documented nor consistent across teams.
- Single-model fragility — off-the-shelf approaches treat the forecasting horizon as one problem, when short, medium, and long horizons require different model families.
How does the AiSPRY solution work?
AiSPRY designed the Supershakti Commodity Forecasting System around a single principle: no single model is right for every commodity, every horizon, every market regime. The platform combines statistical, machine-learning, and deep-learning models — each playing to its strength — and uses an ensemble layer to produce final forecasts with horizon-specific model weighting and backtested confidence intervals.
Data foundation — historical and live signals
- Commodity prices — coal benchmarks and iron-ore price history across spot and contract markets
- Production volumes — internal mine output, shipment, and dispatch records
- Market indices — steel sector indices, energy benchmarks, freight rates, and related commodity correlations
- Demand signals — customer order books, contract pipelines, and industry shipment data
- Economic indicators — GDP growth, FX rates, inflation, interest rates, and key sectoral indicators
- Seasonality & calendar — monsoon impact, festive demand, fiscal-year cycles, and known event calendars
Statistical, ML, and deep-learning models
- Statistical time-series — ARIMA, SARIMA, exponential smoothing, and Holt-Winters built using statsmodels for interpretable, fast-to-retrain short-horizon forecasting
- Machine-learning ensembles — XGBoost regressors and Random Forests on scikit-learn for non-linear feature interactions across wide exogenous signal spaces
- Deep-learning recurrent — Long Short-Term Memory (LSTM) networks in TensorFlow / Keras for long-range temporal dependencies in medium- and long-horizon forecasts
- Feature engineering — stationarity transforms, lag features, rolling statistics, trend/seasonality/residual decomposition, and exogenous joins
- Disciplined splits — train, validation, and holdout splits that prevent look-ahead bias
Ensemble layer — the final forecast
- Combines statistical, ML, and deep-learning families using horizon-specific weights
- ARIMA-family models dominate short horizons; tree-based ensembles dominate medium horizons; LSTM and blends dominate long horizons
- Backtesting drives the weighting decisions
- Confidence intervals calibrated against historical performance
- Business sees not just a number, but the band of likely outcomes around it
See the commodity forecasting platform in action
A walkthrough of the Supershakti Commodity Forecasting System — data ingestion across prices, production, and macro signals, the hybrid model ensemble, horizon-aware forecasts, and confidence-banded outputs flowing into procurement, hedging, and inventory decisions.
Supershakti Commodity Forecasting — hybrid ensemble in action
Click to play · ARIMA + XGBoost + LSTM ensemble forecasts
- Hybrid ensemble — statistical, ML, and deep-learning models each playing to their strength
- Horizon-aware weighting — short, medium, and long horizons treated as distinct problems
- Calibrated confidence bands — every forecast accompanied by a backtested likelihood range
- Operational integration — outputs flow into procurement, hedging, production planning, and inventory optimisation
What is the solution architecture?
The architecture is organised as a five-layer pipeline: data sources, data engineering and feature pipeline, model ensemble, ensemble scoring, and business consumption. Each layer has a clearly defined contract with the next — feature engineering does not contaminate raw sources, models cannot see future data during training, the ensemble layer is the only place forecasts are combined, and consumption applications read final forecasts (with confidence intervals) rather than touching individual models. This separation makes the platform auditable, retrainable, and extensible to additional commodities over time.
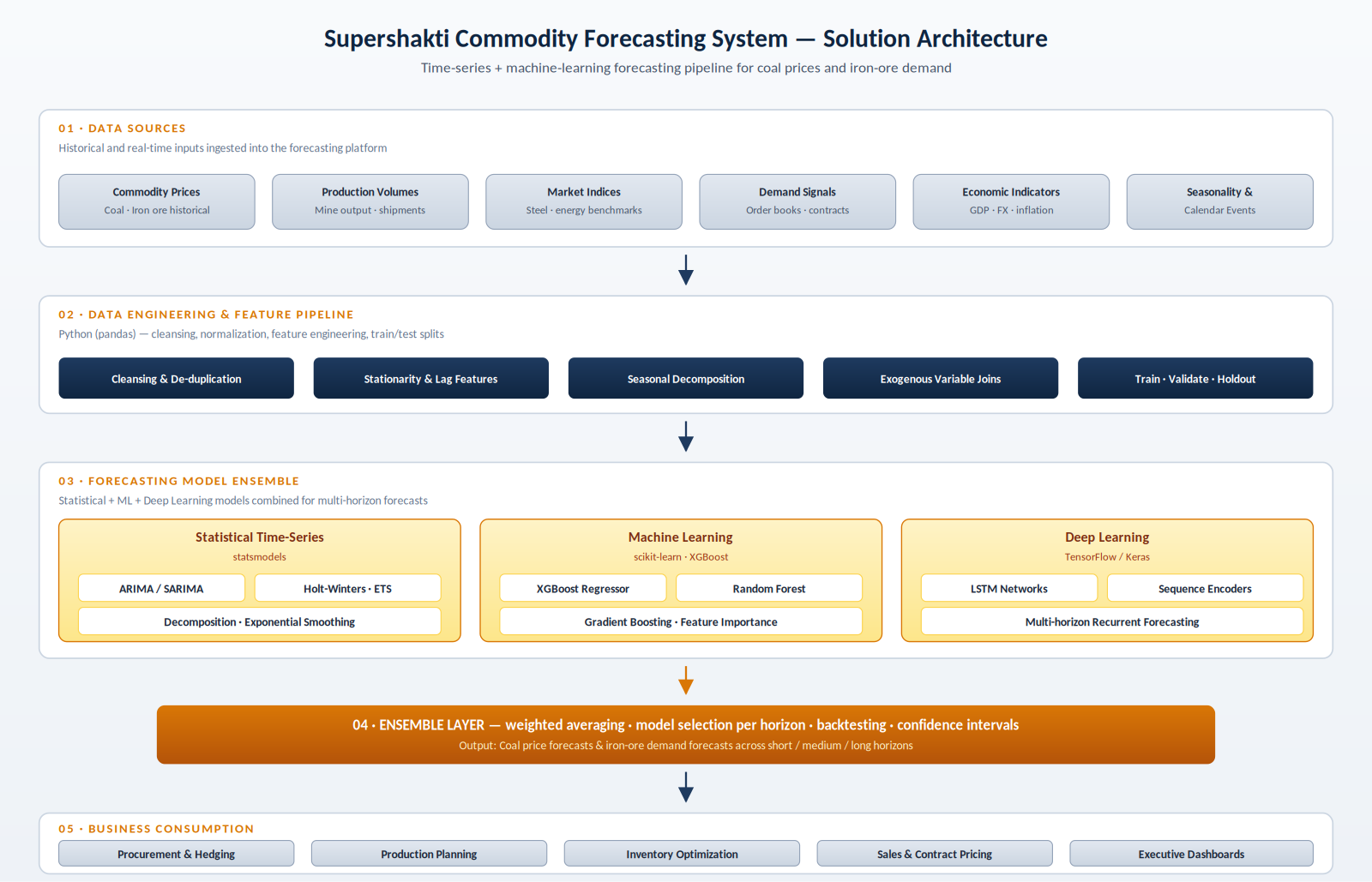
What were the technical design choices?
The platform was engineered around four constraints that shape any forecasting system intended to drive real operational decisions, not just executive presentations.
Python-native, reproducible, and auditable
- Entire stack is Python-native — pandas, statsmodels, scikit-learn, XGBoost, TensorFlow / Keras
- Every model is version-controlled
- Every training run is reproducible
- Every forecast can be traced back to the inputs and model versions that produced it
Horizon-aware model selection
- Short, medium, and long horizons treated as separate problems
- ARIMA-family models dominate short horizons
- Tree-based ensembles dominate medium horizons where exogenous signals matter
- LSTM and ensemble blends dominate long horizons where sequence structure matters most
- Enforced in the ensemble layer's weighting logic
Confidence intervals, not just point forecasts
- Every forecast accompanied by a calibrated confidence band derived from backtesting
- Procurement teams see the 80% band of likely prices, not just a single number
- Decision-making is grounded in uncertainty, not false precision
Designed for retraining, not one-off training
- Commodity markets shift regimes — models are routinely retrained on the latest data
- Ensemble weights are periodically recalibrated
- Feature importance is monitored for drift
- The system improves over time rather than ageing into irrelevance
What is the measurable business impact?
The platform was evaluated on two principal axes — forecast accuracy against held-out historical data, and downstream business impact across procurement, inventory, and production planning. Both axes confirmed the value of the hybrid ensemble approach.
Forecast accuracy
- 89% forecast accuracy across blended horizons on held-out test windows
- Hybrid ensemble materially outperforms each individual model family in isolation
- Validates the horizon-specific weighting design
- Confidence bands calibrated against historical performance
Inventory and procurement
- 70% reduction in inventory carrying cost achieved
- Working capital freed up, yard space released
- Exposure to commodity price declines materially reduced
- Sharper procurement and hedging decisions against forecasted trajectories
Production planning and organisational alignment
- Iron-ore demand forecasts give production planning a forward signal
- Mills ramp output ahead of demand inflections rather than chasing them
- Smoother operations and reduced cost of unplanned run-rate changes
- A single, auditable source of forecasts replacing patchwork spreadsheets across procurement, planning, sales, and finance
Supershakti Commodity Forecasting — frequently asked questions
This section answers the questions most often asked about the Supershakti Commodity Forecasting System. Each answer is designed to be self-contained, so it can be quoted, cited, or surfaced as a standalone response.