Project facts & technologies
A citation-friendly summary of the Uttarakhand GenAI Investor Facilitation Platform — client, scope, technology, and headline outcomes.
- Client
- Government of Uttarakhand — investor facilitation
- Industry segment
- Government, Public Sector, Investment Promotion
- Engagement type
- GenAI chatbot platform — design, build, and deployment
- Query resolution rate
- 94% — investor queries fully resolved by the chatbot
- Processing time reduction
- 60% reduction in time-to-answer for investor queries
- Document corpus
- Government orders, policies, gazettes, investment schemes, approval procedures, department FAQs
- Source document state
- Mostly scanned PDFs and non-searchable images — handled via OCR
- Document ingestion
- OCR + layout parsing + chunking + metadata tagging + embedding generation
- Retrieval foundation
- Vector store with semantic embeddings and structured metadata filters
- RAG orchestration
- LangChain — query understanding, retrieval, generation, citation
- Large language model
- GPT-4 — grounded in retrieved government context
- Citation approach
- Every answer references the originating government document
- Guardrails
- Refusal on out-of-scope queries · hallucination prevention · source verification
- Channels
- Investor portal, web widget, mobile, department admin console
- Cloud platform
- AWS — document storage, OCR pipeline, vector store, LLM orchestration
Why is government investor information so hard to navigate?
Every state government in India runs an investment promotion mandate. Schemes are announced, sectoral policies are issued, gazette notifications go out, and procedural orders flow continuously from departments to the field. The information itself is public — government orders, policies, and gazettes are official publications — but accessing the right piece of information at the right moment, when an investor is trying to decide whether and how to set up business, is a different challenge entirely.
Most government documents predate digital workflows. They live as scanned PDFs and non-searchable images, organised by date and department rather than by what an investor would actually want to ask. Even when the document exists, finding it requires knowing which department issued it, what the order number was, what year it was issued in, and whether it has been superseded by a later notification. For an investor evaluating a sector for the first time, that knowledge does not exist — and acquiring it consumes time that translates directly into delayed investment decisions.
What problem does the investor chatbot solve?
Investors struggled to navigate complex government policies, orders, and gazettes, creating barriers to investment and slowing the business facilitation process. The platform needed to address four specific failure modes that no traditional portal could close on its own.
Key challenges
- Government documents were not searchable — most of the corpus existed as scanned PDFs and image-based files where keyword search could not see inside the content.
- Navigation depended on institutional knowledge — finding the right policy required knowing which department had issued it, which year, and whether it had been superseded.
- Investor queries piled up at the facilitation desk — routine questions about subsidies, approvals, and procedures consumed capacity that should have gone to case-specific facilitation.
- Answers required citation, not just retrieval — investors making material decisions needed the underlying government document to verify the information and attach as due-diligence evidence.
How does the investor facilitation chatbot work?
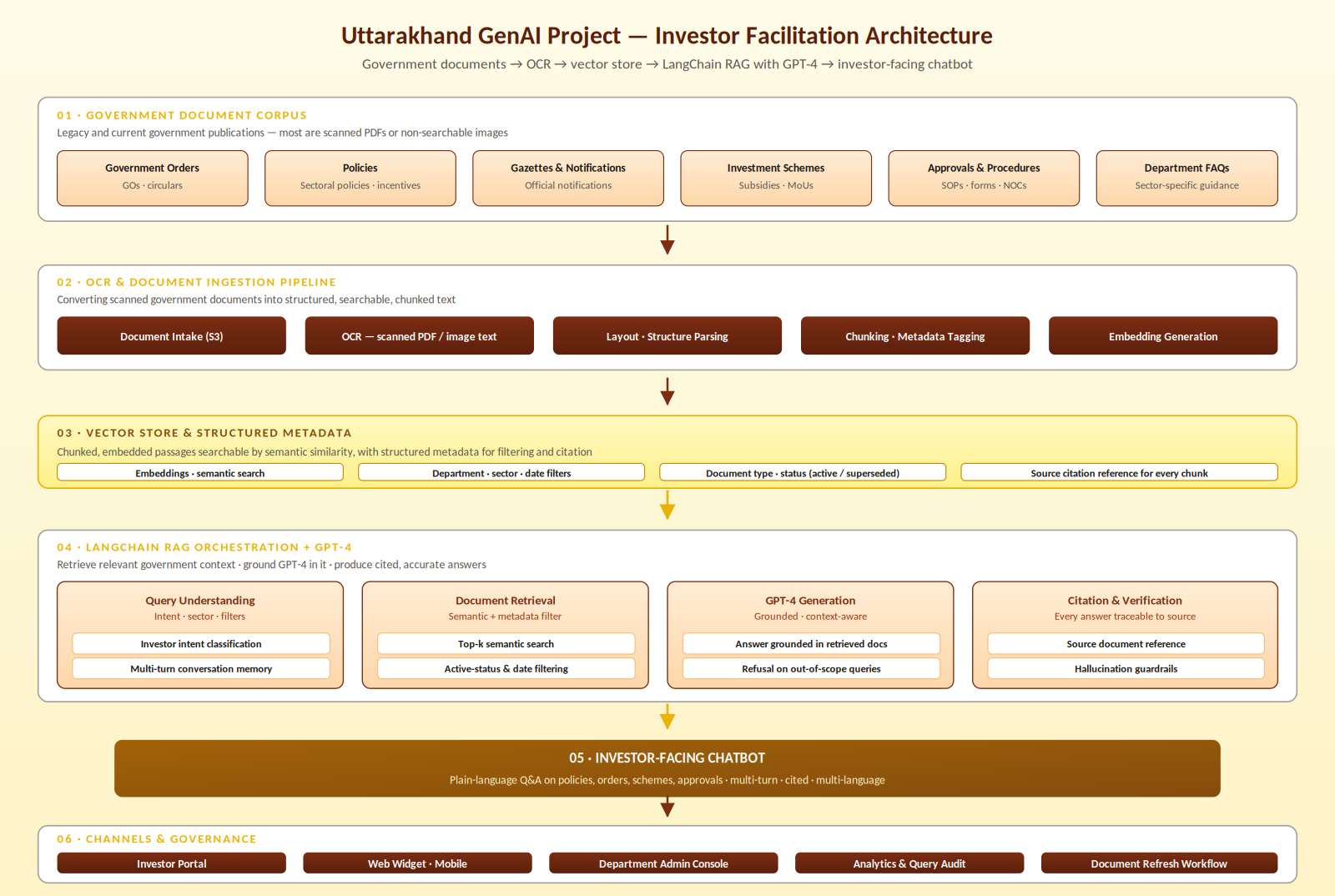
AiSPRY built the Uttarakhand GenAI Investor Facilitation Platform as a six-layer system: a government document corpus, an OCR pipeline that converts legacy scanned material into structured searchable text, a vector store with rich metadata, a LangChain-orchestrated RAG flow on GPT-4 with four cooperating components (query understanding, document retrieval, GPT-4 generation, and citation/verification), an investor-facing chatbot, and the channels through which investors reach it. Every answer must be grounded in a specific, citable government document — not the model's general knowledge.
Document corpus and OCR ingestion
- Government orders, policies, gazettes — GOs, sectoral policies, and notifications across departments
- Investment schemes and procedures — subsidy programmes, MoUs, SOPs, application forms, and NOCs
- OCR + layout parsing — recognises section headers, clause numbering, tables, and signature blocks
- Chunking and metadata tagging — department, sector, date, document type, status, and document reference per chunk
Vector store and LangChain RAG on GPT-4
- Semantic + metadata-filtered retrieval — vector similarity narrowed by department, sector, date, and active/superseded status
- Query understanding — LangChain classifies investor intent, extracts metadata filters, and maintains multi-turn memory
- Grounded GPT-4 generation — the model answers only from retrieved government context, refusing when retrieval fails
- Citation and verification — every answer carries its source document reference; a verification layer flags claims not supported by the cited documents
Channels and governance
- Investor portal and web widget — embedded across state investor-facing pages with mobile access
- Department admin console — government officers see query patterns and trigger document refresh workflows
- Analytics and audit logs — every interaction preserved for governance review
See the investor chatbot in action
A walkthrough of the Uttarakhand GenAI chatbot — an investor asks about sectoral subsidies and approval procedures, the platform retrieves and grounds its answer in the relevant government order, and every response carries the originating document citation.
Uttarakhand GenAI — cited, grounded investor facilitation in action
Click to play · OCR-fed RAG with GPT-4 and source-document citations
- Natural-language investor queries — subsidies, sectoral policies, approval procedures, gazette references
- OCR-driven document access — chatbot retrieves from scanned PDFs the platform has structured
- Active-document priority — metadata filter avoids superseded policies
- Cited answers — every response references the originating government document for verification
What is the architecture of the Uttarakhand GenAI platform?
The architecture is organised as six layers: the government document corpus, the OCR and document ingestion pipeline, the vector store with structured metadata, the LangChain RAG orchestration with GPT-4 (further decomposed into query understanding, retrieval, generation, and citation/verification), the investor-facing chatbot, and the channels and governance layer. Raw scanned documents never reach the chatbot without OCR and structuring; the vector store is the only place where retrieval is grounded; GPT-4 generates only against retrieved context; and every answer carries a traceable citation back to its source document.
How is the platform engineered for government information accuracy?
Government information is exactly the wrong domain for a model to answer from its training data. The platform's design choices ensure every answer is anchored to a specific, current, cited government document.
OCR as a first-class ingestion layer
- Most government information lives in scanned PDFs and non-searchable images
- OCR plus layout parsing plus structured chunking is treated as a dedicated layer, not an afterthought
- This is what allows the platform to cover the actual document estate rather than only born-digital documents
Active-versus-superseded handling in metadata
- Document status (active, superseded, withdrawn) tracked alongside department, sector, date, and type
- Retrieval defaults to active documents only, even when older policies are semantically similar
- A continuous document refresh workflow brings new orders into the corpus as they are issued
Refusal as a guardrail, not a failure mode
- When retrieval cannot find supporting context, GPT-4 is instructed to refuse rather than answer from general knowledge
- A citation-and-verification layer flags any claim not supported by retrieved context before it reaches the investor
- "Please contact the relevant department" is the right response in a government setting, not a fabricated paraphrase
What measurable results did the platform deliver?
The platform was evaluated against the operational pain points it was built to address — query resolution, time-to-answer, citation quality, and the broader effect on investor facilitation capacity.
Investor query resolution
- 94% query resolution rate — chatbot directly answers most investor queries with cited government documents
- 60% reduction in processing time versus the pre-platform baseline
- Remaining queries routed to the appropriate department with full context attached
Capacity and credibility
- Facilitation officer capacity redirected to high-value, case-specific work
- Cited, verifiable answers — investors can click through to the underlying government document
- Always-on multi-channel access via investor portal, web widget, and mobile
Governance and visibility
- Department admin console surfaces query trends and gaps in the document corpus
- Audit logs preserve every interaction for governance review
- Active-document priority ensures investors are never pointed at superseded policy
Uttarakhand GenAI — frequently asked questions
The questions most often asked about the Uttarakhand GenAI Investor Facilitation Platform. Each answer is self-contained, so it can be quoted, cited, or surfaced as a standalone response.