Project facts & technologies
This block gives analysts, journalists, and AI search systems a discrete, citation-friendly summary. Each row is a clean entity-attribute pair.
- Project name
- Wind Turbine Failure Prediction — Predictive Maintenance for Wind Energy
- Industry
- Wind Energy, Renewables, Power Generation
- Use case
- AI-driven prediction of wind turbine component failures and optimized maintenance scheduling
- Core technology
- Machine Learning, MLflow, MongoDB, FastAPI, CI/CD
- Signals monitored
- Vibration, temperature, power output, wind speed and yaw, gearbox and bearing, SCADA
- Models
- Anomaly detection, remaining-useful-life, component-level failure prediction
- Storage
- MongoDB time-series store for high-volume turbine telemetry
- MLOps
- MLflow experiment tracking, model registry, versioning, CI/CD with rollback
- Inference
- FastAPI service layer exposing predictions and schedules
- Outputs
- Failure probability, time-to-failure, optimized maintenance schedules, work orders
- Stakeholder users
- O&M crews, control rooms, asset managers, energy traders, wind-farm leadership
- Maintenance cost outcome
- 40% reduction in maintenance cost
- Energy output outcome
- 15% increase in energy output
- Designed for
- Remote and offshore wind farms with weather-constrained access
Why is wind turbine maintenance such a costly operating problem?
Wind turbines are exceptional machines and brutal ones to maintain. A single utility-scale turbine has hundreds of mechanical and electrical components — gearboxes, bearings, generators, blades, yaw systems, pitch systems, transformers — each with its own failure modes. Multiply that by a wind farm of dozens or hundreds of turbines, often offshore or on mountain ridges, and the maintenance footprint becomes enormous. Every visit to a turbine requires crew time, transportation, and increasingly often a vessel — all of which cost more the further the asset is from the nearest port or road.
Traditional turbine maintenance operates in one of two modes — reactive (wait for failure, then mobilize a crew) and scheduled (replace on a calendar). Neither aligns the maintenance action with the actual condition of the asset. Modern predictive maintenance changes this. Turbines already produce a steady stream of vibration, temperature, power output, wind speed, yaw, gearbox, bearing, and SCADA telemetry that, taken together, predict failure long before it manifests as an outage. ML models trained on that telemetry can flag developing failures days or weeks ahead and schedule maintenance into the weather and operational windows that work for the wind farm.
What problem does the wind turbine platform solve?
Wind farms face challenges with unexpected turbine failures, leading to extended downtime and significant revenue loss due to the remote location and complexity of repairs. AiSPRY designed the platform to solve a specific set of operational challenges together.
Key challenges
- Unexpected component failures — gearbox, bearing, generator, and electrical failures occur without warning under reactive maintenance, taking turbines offline at unpredictable moments.
- Extended downtime — the window between failure and repair on a remote or offshore turbine is long; every hour offline is energy revenue not earned.
- High mobilization cost — remote and offshore farms require crew, transportation, and vessels; emergency mobilizations cost dramatically more than planned ones.
- Weather-constrained access — offshore turbines are accessible only in narrow weather windows; unplanned repairs wait for safe conditions, extending downtime.
- Wasteful scheduled maintenance — calendar-based intervention replaces components with useful life and misses components developing problems between visits.
- Fragmented telemetry and no fleet view — vibration, temperature, power, and SCADA data sit in separate systems; nothing correlates them or prioritizes assets fleet-wide.
How does the wind turbine platform work?
AiSPRY built an AI-powered predictive maintenance platform that monitors every turbine continuously, predicts component failures before they manifest as outages, and optimizes maintenance scheduling around the operational and weather constraints wind operators actually face. The platform follows a five-stage architecture: sensor and SCADA telemetry, streaming ingestion into MongoDB time-series, an ML pipeline combining anomaly detection with remaining-useful-life and component-failure models, a failure prediction and scheduling layer, and an operations surface delivered through FastAPI and dashboards.
Multi-signal sensing and predictive detection
- Multi-signal turbine sensing — vibration, temperature, power output, wind speed and yaw, gearbox and bearing data, and SCADA telemetry stored in MongoDB time-series
- Predictive failure detection — anomaly detection on signal deviations, component-level failure models, remaining-useful-life scoring, and severity prioritization
- Cross-turbine learning — fleet-wide patterns surface failure modes that single-turbine analysis cannot, with continuous retraining as new failures accumulate
MLOps and maintenance scheduling
- MLOps and governance — MLflow tracks experiments and registry; CI/CD enables safe rollouts with rollback; drift and performance monitoring catch model degradation
- FastAPI inference service — exposes predictions and schedules to SCADA, CMMS, and energy-trading systems
- Maintenance scheduling and operations — weather-aware scheduling, crew and vessel planning, CMMS work orders, and energy-output forecasts adjusted for predicted downtime
- Fleet health dashboard — per-turbine drill-down, audit logs, and reports for O&M crews, control rooms, asset managers, and leadership
See wind turbine predictive maintenance in action
A walkthrough of the Wind Turbine Failure Prediction platform — fleet-wide condition monitoring, anomaly and remaining-useful-life models flagging developing component failures, and weather-aware maintenance schedules feeding the CMMS and energy-trading systems.
Wind Turbine Failure Prediction — fleet condition AI in action
Click to play · 24×7 fleet monitoring with predictive maintenance
- Multi-signal correlation — vibration, temperature, power, and SCADA data analysed together for sharper alerts
- Component-level forecasts — failure probability and time-to-failure per gearbox, bearing, generator, and more
- Weather-aware scheduling — repairs aligned with safe access windows and crew / vessel availability
- MLOps governance — MLflow tracking, CI/CD rollouts, rollback support, and audit-grade lineage
What does the wind turbine architecture look like?
The platform follows a five-stage AI/ML pipeline that takes high-volume turbine telemetry and converts it into per-turbine, per-component failure forecasts and optimized maintenance schedules — with full MLOps governance across the lifecycle. Turbine sensors stream data into a MongoDB time-series store, an ML pipeline runs anomaly detection and remaining-useful-life models tracked through MLflow, a failure prediction and scheduling layer produces actionable plans, and a FastAPI service plus fleet health dashboard surface the outputs to SCADA, CMMS, energy-trading systems, and O&M teams.
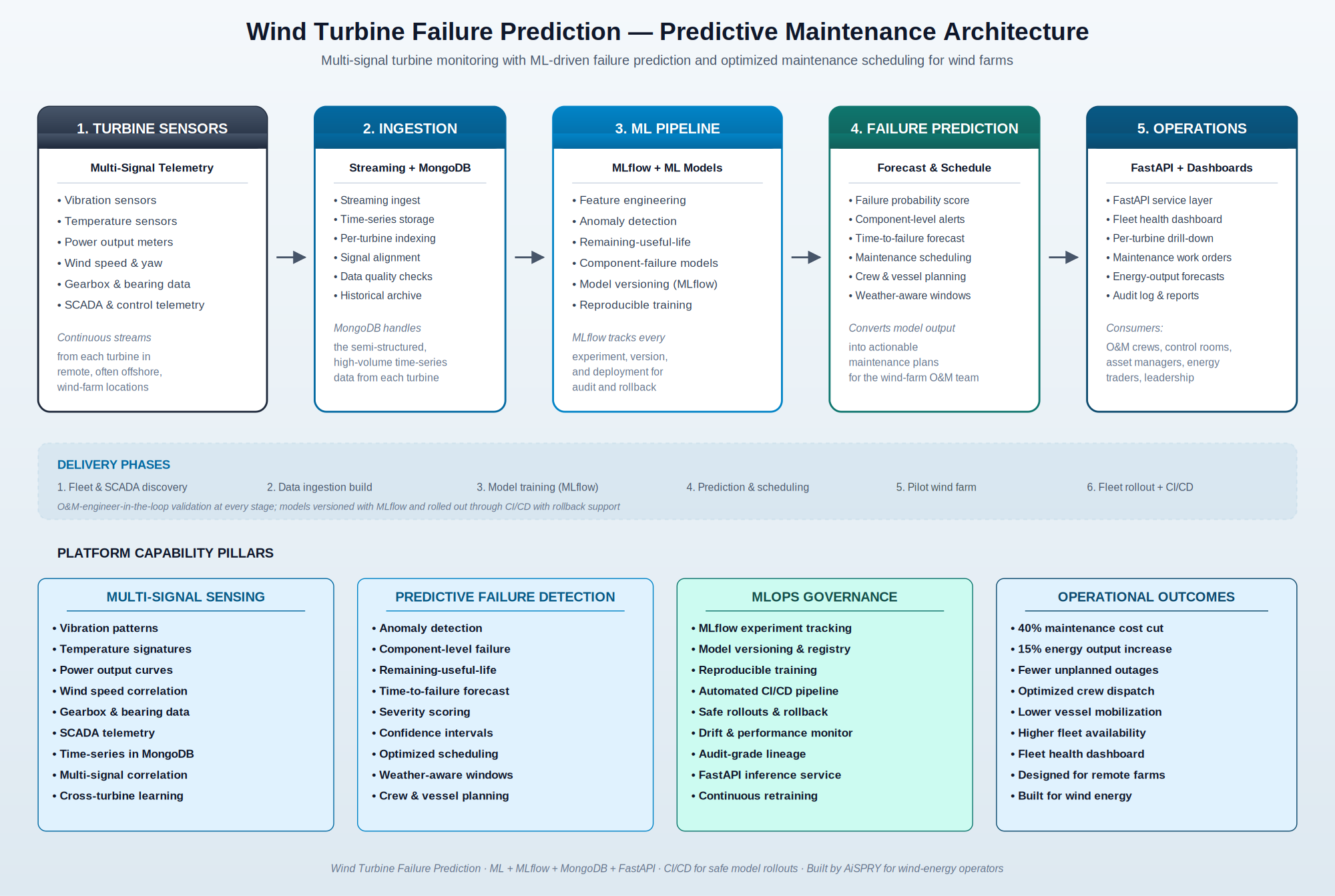
How does the platform handle remote operations, false alarms, and MLOps?
Building a predictive maintenance platform for wind energy — remote, weather-exposed, safety-critical, and tied to direct energy revenue — imposes a specific set of constraints. AiSPRY engineered around four.
Remote and offshore operations
- Every maintenance visit is expensive — platform optimizes against mobilization cost
- Weather-aware scheduling aligns repairs with safe access windows
- Severity scoring helps O&M teams prioritize highest-impact assets
- Designed to operate with intermittent connectivity to remote sites
Multi-signal correlation and MLOps
- Vibration, temperature, and power-output patterns correlated together — not analysed in isolation
- Wind speed and yaw context prevents false positives from operational variation
- MLflow tracks every experiment, version, and deployment for audit
- CI/CD with rollback support so a regressing model can be reverted immediately
- Drift and performance monitoring catches model degradation in production
Integration with wind-farm systems
- FastAPI exposes clean REST interfaces to SCADA, CMMS, and trading systems
- MongoDB-backed time-series storage scales with fleet size and telemetry volume
- Maintenance schedules feed the CMMS as work orders, not PDF reports
- Energy-output forecasts feed trading and dispatch systems
What measurable results does the wind turbine platform deliver?
The platform was engineered against two headline metrics — maintenance cost and energy output — both moved sharply in the right direction. Beyond the headline numbers, the platform shifts wind-farm O&M from reactive and calendar-driven to predictive and condition-driven.
Maintenance cost and efficiency
- 40% reduction in maintenance cost across the fleet
- Fewer emergency mobilizations to remote and offshore turbines
- Lower vessel and crew dispatch cost through optimized scheduling
- Reduced replacement of components that still had useful life
Energy output and availability
- 15% increase in energy output through higher fleet availability
- Fewer unplanned outages directly converts into more megawatt-hours delivered
- Repairs scheduled into low-wind windows, not peak-generation hours
- Component failures caught early shorten the eventual repair window
Governance and decision support
- Continuous 24×7 fleet condition monitoring replaces episodic inspection
- Fleet health dashboard gives leadership a single view across the operation
- MLOps governance with MLflow and CI/CD keeps models production-safe
- Audit-grade lineage supports asset management and regulatory review
Wind Turbine Failure Prediction — frequently asked questions
Below are the most common questions about how the platform works, what it predicts, and how it integrates with existing wind-farm operations.